Industrial Unified Namespace (UNS) – und jetzt?
Doch während sich der UNS als bewährte Dateninfrastruktur etabliert, bleibt die Entwicklung innovativer Industrie 4.0 Anwendungen auf Basis von UNS-Daten eine anspruchsvolle Aufgabe. Der Grund: Bei der Umsetzung dieser Anwendungsfälle treffen verschiedene Datenverarbeitungskonzepte mit unterschiedlichen Anforderungen an die Datenverarbeitung aufeinander:
Die Integration dieser Konzepte in den UNS ist anspruchsvoll und bringt technische sowie organisatorische Herausforderungen mit sich. Dieses Whitepaper zeigt, wie die Erweiterung des UNS zum #shared.UnifiedNamespace (#shared.UNS) diese Herausforderungen adressiert und Unternehmen eine effiziente, skalierbare und zukunftssichere Datenstrategie ermöglicht.
Der Industrial Unified Namespace (UNS)
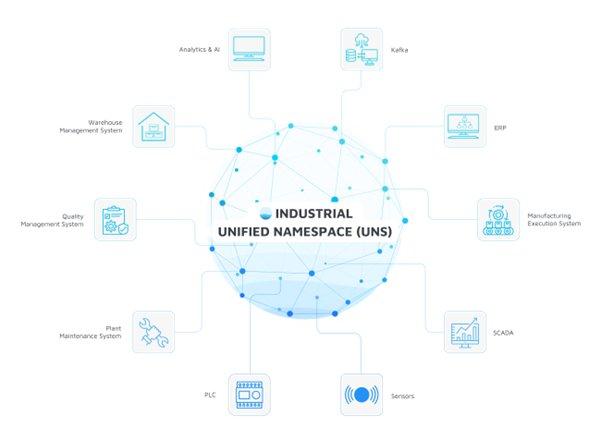
Die moderne Industrie produziert und verarbeitet enorme Mengen an Daten – von Sensordaten über Produktionskennzahlen bis hin zu unternehmensweiten ERP-Informationen. Doch oft bleiben diese Daten in Silos gefangen, verteilt auf verschiedene Systeme und Plattformen, die nur begrenzt miteinander kommunizieren können. Der Industrial Unified Namespace schafft eine einheitliche Schnittstelle, die alle relevanten Daten in Echtzeit zugänglich macht und so die Grundlage für eine vernetzte, datengetriebene Produktion bildet.
Was ist der UNS?
Ein Industrial Unified Namespace dient als Single-Source-of-Truth für alle Daten in einer Industrieumgebung. Alle relevanten Produktions- und Geschäftsdaten werden dabei in einer einheitlichen, hierarchischen Namensstruktur organisiert und in Echtzeit bereitgestellt. Technisch realisiert wird dies meist durch einen zentralen Message Broker (häufig ein MQTT-Broker), der als Daten-Hub für sämtliche Kommunikationsströme dient. Über diesen Broker veröffentlichen Datenproduzenten (z.B. Sensoren, Maschinen, SPSen) ihre Informationen, und Datenkonsumenten (z.B. MES, Analytics-Plattformen) abonnieren sie – entkoppelt und ereignisgesteuert über das Publish/Subscribe-Muster. Dadurch ersetzt der UNS zahlreiche individuelle Punkt-zu-Punkt-Schnittstellen durch eine zentrale Integrationsschicht.
Kernaspekte und Vorteile des UNS:
Der UNS bietet zahlreiche Vorteile, darunter die nahtlose Datenintegration, Interoperabilität, Skalierbarkeit und eine offene Architektur. Diese Vorteile tragen dazu bei, die Effizienz der Datenverwaltung zu steigern und die Geschäftsprozesse zu optimieren.
Herausforderungen des Industrial Unified Namespace
Trotz der zahlreichen Vorteile bringt die Einführung eines Industrial Unified Namespace auch Herausforderungen mit sich. Eine zentrale Herausforderung ist die Gewährleistung einer performanten, skalierbaren und sicheren Dateninfrastruktur, die den Anforderungen verschiedener Anwendungsfälle gerecht wird. Hierbei haben Anwendungsfälle häufig individuelle Anforderungen an die Ausfallsicherheit, Latenzen, Datenstruktur, -formate, etc. Wie kann in einem zentralen Namespace diese Individualität gewährleistet werden? Zudem unterscheiden sich die Zielnutzer der Daten, was die Standardisierung und Datenharmonisierung innerhalb des UNS erschwert. Und nicht zuletzt stellt die Integration und Kombination verschiedener Datenverarbeitungskonzepte wie Streaming, Batch und Big Data Unternehmen häufig vor Herausforderungen.
[*]Big Data (z. B. Data Lakehouse-Architekturen)
Ein effektives Architekturdesign muss daher skalierbare Speicherlösungen, eine performante Verarbeitung und intelligente Integrationsmechanismen kombinieren, um die verschiedenen Datenströme zusammenzuführen und eine ganzheitliche Sicht auf industrielle Prozesse zu ermöglichen.
Der #shared.UnifiedNamespace
Die Erweiterung des Unified Namespace hin zum #shared.UnifiedNamespace adressiert die genannten Herausforderungen. Dabei stehen die UNS Dezentralisierung und Differenzierung der Datenströme im UNS im Zentrum. Im Gegensatz zum traditionellen, zentralisierten UNS mit einem zentralen Massage Broker setzt der #shared.UNS damit auf eine dezentrale und anwendungsorientierte Architektur.
Was ist der #shared.UNS?
Während der UNS heute oftmals als zentraler Broker verstanden wird, baut der #shared.UNS auf einem dezentralen Architekturprinzip auf. Konkret bedeutet dies, dass mehrere spezialisierte UNS-Instanzen auf Edge-Ebene (#edge.UNS) existieren, die für verschiedene Anlagen und Produktionsumgebungen angepasst sind.
Jede #edge.UNS bildet die Struktur einer Anlage in einem standardisierten Datenmodell ab. Diese sind unabhängig von den individuellen Anforderungen der jeweiligen Anwendungsfälle. Für jeden Anlagentypen ist der #edge.UNS von der Struktur identisch, die übertragenen Kanäle (Desriptions) können sich aber unterscheiden. Dadurch wird eine hohe Skalierbarkeit und Wiederverwendbarkeit ermöglicht. Ein übergeordnetes System oder Broker kann diese lokalen Namespaces bei Bedarf und je nach Anwendungsfall aggregieren. Damit werden die Individualität und Dynamik typischer Anwendungsfälle nicht bereits im #edge.UNS Namespace abgebildet, wodurch die Komplexität bei der Erstellung und dem Betrieb des UNS erheblich reduziert wird. Das bewährte Prinzip der späten Variantenbildung steigert nicht nur die Effizienz und Flexibilität in der Produktion, sondern optimiert auch die Dateninfrastruktur für eine agile und skalierbare Nutzung.
Exkurs: Alternativ zu dezentralen #edge.UNS Instanzen könnte ein leistungsfähiges Broker-Cluster das gesamte Unternehmen zentral bedienen. Moderne MQTT-Broker lassen sich in Clustern betreiben, um Last auf mehrere Knoten zu verteilen und eine hohe Ausfallsicherheit zu gewährleisten. Diese zentralisierte Architektur kann auf Unternehmensebene die Administration vereinfachen, da eine einzige Instanz verwaltet wird. Herausfordernd sind jedoch mögliche Bandbreitenengpässe und erhöhte Latenzen zwischen Standorten – ein häufig kritischer Faktor insbesondere in Fertigungsumgebungen. Im Gegensatz hierzu werden durch lokale Instanzen geringe Latenz und Entkopplung auf Werksebene gewährleistet. Zudem lässt sich die Datenflut einschränken, da nicht alle Daten global übertragen werden müssen, sondern gefiltert werden können. Dieser verteilte Ansatz erfordert jedoch eine sorgfältige Definition der Namespaces, um eine konsistente Struktur sicherzustellen.
Neben dem #edge.UNS gibt es noch weiter Namespaces, wie z.B. #erp.UNS, #qms.UNS oder #hkd.UNS. Diese strukturieren die Daten aus den Enterprise Systemen, bzw. die verschiedenen Eingaben von Mitarbeitern.
Der "Human Knowledge Data“ UNS (#hkd.UNS) ist einer der wichtigsten Datenquelle, um zusätzliches Wissen (persönliches Wissen und persönliche Erfahrungen aus der Fertigung) in die Auswertungen zu integrieren.
Wir benötigen dieses Wissen der Experten!
Im #shared.UNS gibt es aus diesem Grund den #hkd.UNS: Nur das menschliche Wissen hilft uns z.B. Qualitätsdaten (#qms.UNS) richtig zu strukturieren und zu interpretieren. Nur Experten können Prozesse definieren, um z.B. Qualitätsdaten (#qms.UNS) mit den Daten aus den Anlagen (#edge.UNS) und dem ERP (#erp.UNS) zu verknüpfen, um daraus z.B. Schwachstellen in den Fertigungsprozessen abzuleiten.
Von der #edge.UNS teilt i-flow die Daten in relevante Datenströme auf. Einzelne Werte werden dabei automatisch gemäß einer vordefinierten Methode für spezifische Services optimiert und anschließend im jeweiligen Datenmodell veröffentlicht.
Dies ermöglicht eine gezielte Integration relevanter Daten in den jeweiligen Anwendungsfall. Dabei können die einzelnen Services hinsichtlich Ihrer individuellen Anforderungen an Kritikalität, Latenz, Redundanz etc. optimiert werden. Ein Beispiel: Durch die Optimierung von Datenmenge und -format kann die Latenzzeit für spezifische Services deutlich reduziert werden. Dies kann bei produktionskritischen Anwendungsfällen, wie. z.B. der Rückverfolgbarkeit, von großer Bedeutung sein. Eine Anlage kann nicht weiter produzieren, solange die Prozess- und Qualitätsdaten für ein sicherheitsrelevantes Bauteil nicht in die Datenbank geschrieben sind.
Zur Anzeige und Auswertung der Daten, werden an die drei Daten-Services entsprechende Dashboards angebunden. Dashboards und Echtzeit-Analysen sind ein wesentlicher Bestandteil des #SharedUNS und haben schlussendlich zum Ziel, die Effizienz der Fertigung zu steigern. Durch die Visualisierung von Daten können Potenziale identifiziert und fundierte Entscheidungen getroffen werden.
Implementierung des #shared.UNS
Die Implementierung des #shared.UNS erfolgt in mehreren Schritten:
Fazit
Die digitale Transformation der industriellen Produktion erfordert eine leistungsfähige und flexible Datenarchitektur. Der Industrial Unified Namespace (UNS) hat sich als entscheidende Lösung zur Vernetzung, Integration und Harmonisierung von Produktionsdaten etabliert.
Der #shared.UnifiedNamespace stellt eine Erweiterung des Unified Namespace (UNS) Konzepts dar und bietet Unternehmen eine effiziente und flexible Möglichkeit ihre Daten zu verwalten und Fertigungsprozesse zu optimieren. Durch die klare Trennung der Datenströme in Streaming-Daten, Batch Daten und Big Data können spezifische Anforderungen erfüllt und gleichzeitig die Komplexität der Datenstruktur erheblich reduziert werden.
Mit dem #SharedUNS erhalten Unternehmen eine modulare, leistungsfähige und zukunftssichere Datenstrategie, die sich nahtlos in bestehende Industrie 4.0-Konzepte integriert. Die strukturierte Implementierung über i-flow und TT PSC gewährleistet eine effektive Umsetzung.
Warum i-flow und TT PSC?
Erfahrung und Expertise: Mit 30 Jahren Erfahrung in der Automobilindustrie, einschließlich der Arbeit mit verschiedenen OEMs, entwickeln wir schon lange Standardlösungen für die Fertigung.
Langjährige Grundprinzipien: Unsere Methoden und Prinzipien sind seit Jahrzehnten bewährt und etabliert. Der #shared.UNS basiert auf diesen Erfahrungen und einer konstanten Weiterentwicklung der Systematiken und Technologien. Die Datentypen in der Fertigung sind nahezu gleichgeblieben, die Systematiken haben sich über die Jahre angepasst.
Enterprise-Umgebungen: Wir sind spezialisiert auf komplexe Enterprise-Umgebungen und kennen die spezifischen Herausforderungen.
Vertrautheit mit Datenmodellen: Wir kennen sehr viele Datenmodelle. Wie haben daraus kundenspezifischen Modelle abgeleitet und können diese effektiv anwenden.
Systematik und Werkzeugkasten: Unsere systematische Herangehensweise und unser erprobter Software- und Vorgehens-Werkzeugkasten gewährleisten effiziente Lösungen.
Kein Vendor Lock-in: Unsere Lösungen sind unabhängig von großen Legacy Softwarelösungen und nutzen vorhandene Systeme basierend auf Microservices. Wir bringen eine bewährte Systematik und ein strukturiertes Vorgehensmodell mit.
Datenexpertise: Unsere Experten für Datentypen und Factory DataOps optimieren Datenströme in Zusammenarbeit mit Produktionsexperten. Gleichzeitig kommen wir aus dem Shopfloor und verstehen die Herausforderungen, Prozesse und Menschen.
Basis und Zusammenarbeit: Wir bringen die grundlegende Infrastruktur mit, während Ihr Team die spezifischen Anpassungen zur Implementierung in Ihrer Umgebung gemeinsam mit uns vornimmt.
Skalierbarkeit und Belastungstests: Wir bieten skalierbare Lösungen und führen routinemäßig umfassende Belastungstests für durch.
Demo-Umgebung: Unsere Demo-Umgebung kann Ihre Daten verarbeiten und das System testen, um die Funktionalität zu demonstrieren
Über i-flow: i-flow ist ein Unternehmen für industrielle Software mit Sitz in Süddeutschland. Wir bieten produzierenden Unternehmen die weltweit intuitivste Software zur Vernetzung von Fabriken. Täglich über 400 Millionen Datenoperationen in produktionskritischer Umgebung demonstrieren die Skalierbarkeit der Software und das tiefe Vertrauen, das unsere Kunden in i-flow setzen. Unser Erfolg basiert auf enger Zusammenarbeit mit Kunden und Partnern weltweit, darunter namhafte Fortune-500-Unternehmen und Branchenführer wie Bosch.
Wir sind ein internationaler System Integrator mit Hauptsitz in München. Durch die Kombination unseres technologischen Wissens in den Bereichen Cloud, AI und Streaming mit unseren Produktions- und Datenkompetenz bieten wir optimierte Lösungen für Fertigungs- und Produktionsprozess an. Wir haben mehr als 30 Jahre Erfahrung im Bereich der Digitalen Fabrik. Zu unseren Kunden gehören großen deutschen Automobilhersteller und namhafte Unternehmen in der Zulieferindustrie.
[url=https://www.ttpsc.com]https://www.ttpsc.com[/url]
Transition Technologies PSC Germany GmbH
Dingolfinger Str. 15
81673 München
Telefon: +49 171 6152747
http://www.ttpsc.com
![]()